الفصل الثالث
التعلم الآلي: كيف يتعلم الذكاء الاصطناعي من البيانات؟
الدماغ الرقمي: أنواع التعلم وكيف تكتسب الآلة الخبرة من البيانات.
تخيل أن الذكاء الاصطناعي لديه "دماغ رقمي" خاص به، وهذا الدماغ يتعلم ويكتسب الخبرة تماماً كما يفعل دماغ الإنسان، ولكن بطريقة مختلفة. هذا هو جوهر التعلم الآلي (Machine Learning)، وهو فرع من فروع الذكاء الاصطناعي يركز على تمكين الأنظمة من التعلم من البيانات دون برمجة صريحة لكل خطوة. بدلاً من أن تقول للآلة "افعل كذا بالضبط"، أنت فقط توفر لها البيانات وتتركها تتعلم الأنماط والقرارات بنفسها.
هناك ثلاثة أنواع رئيسية لكيفية تعلم الآلة من البيانات:
النوع الاول :
التعلم الخاضع للإشراف (Supervised Learning): "الآلة كطالب يتعلم من المعلم"
هذا النوع من التعلم يشبه تماماً الطالب الذي يتعلم من معلم لديه الإجابات الصحيحة. في التعلم الخاضع للإشراف، تُعطى الآلة بيانات مُصنفة (Labeled Data)، أي بيانات نعرف نتيجتها الصحيحة مسبقاً.
كيف يعمل؟
- البيانات المُصنفة: أنت تزود النموذج ببيانات تحتوي على "إجابات" أو "تصنيفات" صحيحة.
- التعلم من الأمثلة: يتعلم النموذج من هذه الأمثلة المصنفة كيف يربط بين المدخلات والمخرجات الصحيحة. كلما زادت الأمثلة التي يتعلم منها، زادت دقته.
- التنبؤ: بعد التدريب، يصبح النموذج قادراً على التنبؤ بالنتائج لبيانات جديدة لم يرها من قبل.
مثال: تدريب نظام لتمييز رسائل البريد العشوائي (Spam Detection)
تخيل أن لديك صندوق بريد إلكتروني، وتريد أن يفصل الذكاء الاصطناعي بين رسائل البريد العادية (In-box) والرسائل المزعجة (Spam).
- المعلم (أنت/البيانات المُصنفة): ستقوم بتزويد نموذج التعلم الآلي بآلاف الرسائل الإلكترونية. لكن الأهم أنك ستُخبر النموذج عن كل رسالة: "هذه الرسالة عادية" أو "هذه الرسالة مزعجة". أنت هنا تعمل كمعلم يصنف البيانات.
- الطالب (النموذج): سيبدأ النموذج بتحليل خصائص كل رسالة (الكلمات المستخدمة، اسم المرسل، الروابط الموجودة، حجم الرسالة). يتعلم الأنماط التي تميز الرسائل العادية عن المزعجة (مثلاً، رسائل السبام قد تحتوي على كلمات مثل "جائزة"، "اربح الآن"، أو روابط مشبوهة).
- الاختبار والتطبيق: بمجرد أن يتعلم النموذج جيداً، عندما تأتيه رسالة جديدة غير مصنفة، سيستخدم ما تعلمه من آلاف الأمثلة السابقة ليقرر ما إذا كانت "عادية" أو "مزعجة" ويضعها في المكان الصحيح.
تطبيقات أخرى للتعلم الخاضع للإشراف:
- التعرف على الوجوه: تزويد صور لأشخاص مع أسمائهم ليتعلم النموذج التعرف عليهم.
- التنبؤ بأسعار المنازل: تزويد بيانات عن منازل (المساحة، عدد الغرف، الموقع) مع أسعار بيعها الفعلية، ليتعلم النموذج التنبؤ بأسعار المنازل الجديدة.

النوع الثاني :
التعلم غير الخاضع للإشراف (Unsupervised Learning):
"الآلة كباحث يكتشف الأنماط الخفية في البيانات"
تخيل أنك دخلت إلى مكتبة ضخمة مليئة بالكتب، ولكن لا يوجد بها أي تصنيف أو فهرسة. مهمتك هي أن تقوم أنت، كباحث، بقراءة هذه الكتب وتجميعها في مجموعات بناءً على محتواها المتشابه، دون أن يخبرك أحد مسبقاً عن أي شيء. هذا هو جوهر التعلم غير الخاضع للإشراف.
في هذا النوع من التعلم، تُعطى الآلة بيانات غير مُصنفة (Unlabeled Data). هذا يعني أننا لا نعرف "الإجابات الصحيحة" أو التصنيفات المسبقة للبيانات. مهمة النموذج هنا هي اكتشاف الأنماط، العلاقات، أو البنى المخفية داخل البيانات بنفسه.
كيف يعمل؟
- بيانات غير مصنفة: أنت تزود النموذج ببيانات خام ليس لها أي تصنيفات أو مخرجات معروفة مسبقاً.
- البحث عن الأنماط: يبدأ النموذج بتحليل البيانات بحثاً عن أوجه التشابه أو الاختلافات المتكررة.
- التجميع أو التخفيض: يقوم النموذج بتجميع البيانات المتشابهة معاً في "مجموعات" (Clusters)، أو يقلل من تعقيد البيانات مع الاحتفاظ بالمعلومات الأساسية.
مثال: تجميع العملاء المتشابهين في السلوك لتقديم توصيات
تخيل متجراً إلكترونياً لديه آلاف العملاء وسجلات لمشترياتهم وعادات تصفحهم، لكنه لا يعرف كيف يصنفهم. هنا يمكن استخدام التعلم غير الخاضع للإشراف:
البيانات (غير المصنفة): يتم إعطاء نموذج التعلم الآلي بيانات كل عميل: المنتجات التي اشتروها، الصفحات التي زاروها، الوقت الذي قضوه في التصفح، عدد النقرات. لا يوجد هنا تصنيف مسبق يقول "هذا العميل يحب الأجهزة الإلكترونية" أو "هذا العميل مهتم بالملابس".
الباحث (النموذج): يبدأ النموذج بتحليل كل هذه البيانات الضخمة. قد يكتشف أن:
- مجموعة من العملاء يشترون دائماً أحدث الهواتف الذكية والإكسسوارات التقنية.
- مجموعة أخرى تشتري كتباً وروايات بشكل منتظم وتزور صفحات المراجعات الأدبية.
- مجموعة ثالثة تهتم بمنتجات العناية بالبشرة والمكياج.
التجميع (Clustering): يقوم النموذج تلقائياً بوضع هؤلاء العملاء المتشابهين في السلوك ضمن مجموعات أو "فئات" منفصلة. هو من يكتشف هذه الفئات بناءً على البيانات نفسها، وليس بناءً على تصنيف مسبق منك.
التوصيات: بعد تجميع العملاء، يصبح بإمكان المتجر تقديم توصيات مخصصة لكل مجموعة. فإذا جاء عميل جديد ووجد النموذج أن سلوكه يشبه "مجموعة محبي التقنيات"، فسيقترح عليه أحدث الأجهزة.
لماذا هو مهم؟
هذا النوع من التعلم مفيد جداً عندما لا يكون لدينا معلومات مصنفة مسبقاً، أو عندما نريد اكتشاف أنماط جديدة وغير متوقعة في البيانات. إنه يساعد في فهم هيكل البيانات نفسه.
تطبيقات أخرى للتعلم غير الخاضع للإشراف:
- تحديد المنتجات المتشابهة: تجميع المنتجات التي يشتريها العملاء غالباً معاً (مثل الحليب والسكر)، لمساعدتك في ترتيب المتجر أو عرض العروض.
- اكتشاف الحالات الشاذة (Anomaly Detection): البحث عن نقاط بيانات غير عادية أو "غريبة" قد تشير إلى احتيال أو مشكلة فنية في الشبكات.
- ضغط البيانات: تقليل حجم البيانات مع الاحتفاظ بالمعلومات الأساسية، مما يسرع من معالجتها.
هل أصبح مفهوم التعلم غير الخاضع للإشراف أكثر وضوحاً الآن، وكيف أن الآلة تكتشف الأنماط بنفسها؟ هل يمكنك أن تتخيل سيناريو آخر يمكن أن يستخدم فيه الذكاء الاصطناعي هذا النوع من التعلم؟

النوع الثالث :
التعلم المعزز (Reinforcement Learning):
"الآلة كطفل يتعلم بالمحاولة والخطأ والمكافأة"
تخيل طفلاً صغيراً يحاول تعلم المشي. لا يوجد أحد يخبره بالضبط كيف يحرك كل عضلة. بدلاً من ذلك، هو يحاول، يسقط، ثم يحاول مرة أخرى. عندما ينجح في اتخاذ خطوة، يشعر بالرضا (مكافأة)، وعندما يسقط، يشعر بعدم الارتياح (عقوبة). بمرور الوقت، يتعلم كيف يتخذ الخطوات الصحيحة لتجنب السقوط والمشي بنجاح. هذا بالضبط هو جوهر التعلم المعزز.
في التعلم المعزز، لا يتم تزويد النموذج ببيانات مصنفة مسبقاً، ولا يكتشف أنماطاً في بيانات موجودة. بدلاً من ذلك، يتعلم النموذج من خلال التفاعل مع بيئة معينة. هو يتخذ إجراءات، ويحصل على "مكافآت" أو "عقوبات" بناءً على نجاح أو فشل هذه الإجراءات، ويعدّل سلوكه تدريجياً لزيادة المكافآت وتقليل العقوبات.
المكونات الأساسية للتعلم المعزز:
- الوكيل (Agent): هو "الذكاء الاصطناعي" الذي يتعلم.
- البيئة (Environment): هي العالم الذي يتفاعل معه الوكيل.
- الحالة (State): الوضع الحالي للبيئة (مثلاً، موقع الروبوت في المتاهة).
- الإجراء (Action): القرار الذي يتخذه الوكيل في حالة معينة (مثلاً، التحرك يميناً أو يساراً).
- المكافأة (Reward): إشارة إيجابية أو سلبية يتلقاها الوكيل بعد اتخاذ إجراء.
كيف يعمل؟
- التجربة والخطأ: يبدأ الوكيل في استكشاف البيئة واتخاذ إجراءات عشوائية في البداية.
- المكافأة والعقاب: في كل مرة يتخذ فيها إجراءً، يحصل على مكافأة (نقاط إيجابية) إذا كان الإجراء جيداً ويقربه من الهدف، أو عقوبة (نقاط سلبية) إذا كان الإجراء سيئاً أو يبعده عن الهدف.
- التعلم من النتائج: بمرور الوقت وتكرار آلاف أو ملايين المحاولات، يتعلم الوكيل أي الإجراءات تؤدي إلى أعلى مكافأة في كل حالة. هو يبني "سياسة" أو "استراتيجية" لأفضل سلوك يجب اتباعه.
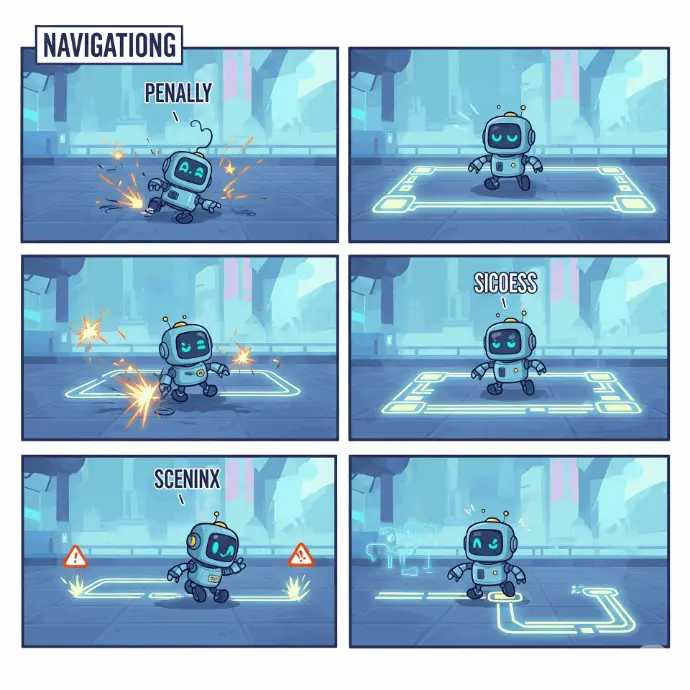
مثال: تدريب روبوت على اجتياز متاهة
تخيل روبوتاً صغيراً مهمته هي إيجاد طريقه للخروج من متاهة.
- الوكيل: الروبوت نفسه.
- البيئة: المتاهة بكل جدرانها وممراتها ومخرجها.
- الحالات: أي مربع يقف فيه الروبوت داخل المتاهة.
- الإجراءات: التحرك لأعلى، أسفل، يمين، يسار.
- المكافآت/العقوبات:
- مكافأة إيجابية كبيرة: إذا وصل الروبوت إلى المخرج.
- مكافأة سلبية صغيرة (عقوبة): في كل خطوة يتخذها (لتشجيعه على إيجاد أقصر طريق).
- عقوبة كبيرة جداً: إذا اصطدم الروبوت بجدار.
- عملية التعلم: في البداية، سيتحرك الروبوت بشكل عشوائي، يصطدم بالجدران مراراً وتكراراً، ويقضي وقتاً طويلاً. لكن في كل مرة ينجح فيها في اتخاذ خطوة جيدة (تجنب جدار، أو يقترب من المخرج)، يتلقى مكافأة. عقله الرقمي (النموذج) يسجل هذه "الخبرة". بعد آلاف بل ملايين "التجارب"، يتعلم الروبوت أفضل مسار للخروج من المتاهة بأقل عدد من الخطوات (أقصى مكافأة).
لماذا هو مهم؟
التعلم المعزز ممتاز للمشكلات التي لا يوجد فيها بيانات مصنفة كثيرة، أو عندما يكون الهدف هو تحسين السلوك بمرور الوقت في بيئة ديناميكية. إنه يُمكِّن الأنظمة من اتخاذ قرارات متتالية لتحقيق هدف طويل المدى.
تطبيقات أخرى للتعلم المعزز:
- القيادة الذاتية: تتعلم السيارات كيف تتخذ قرارات القيادة (التسارع، الفرملة، تغيير المسار) بناءً على مكافآت (الوصول بسلام) وعقوبات (الحوادث).
- ألعاب الفيديو: الأنظمة التي تتعلم كيف تلعب ألعاب الفيديو وتتفوق على أفضل اللاعبين البشريين (مثل AlphaGo في لعبة Go).
- التحكم بالروبوتات: تدريب الروبوتات على أداء مهام معقدة مثل الإمساك بالأشياء أو المشي في بيئات غير مألوفة.
- إدارة المخزون: تحسين قرارات الشراء والتخزين لتقليل التكاليف وزيادة الربحية.