الفصل الثاني
رحلة البيانات: من الجمع إلى التجهيز
البيانات الخام تتحول إلى ذهب: خطوات تجهيز البيانات للذكاء الاصطناعي
تخيل أنك طباخ ماهر وتريد تحضير وجبة شهية. هل يمكنك استخدام المكونات كما هي من السوبر ماركت مباشرة؟ بالطبع لا! ستحتاج إلى غسل الخضروات، تقطيع اللحوم، وقياس المكونات بدقة. البيانات بالنسبة للذكاء الاصطناعي تشبه هذه المكونات الخام تماماً. لكي تصبح مفيدة وقابلة للاستخدام، يجب أن تمر برحلة من التجهيز والمعالجة. هذه الرحلة ضرورية لضمان أن يتعلم الذكاء الاصطناعي من معلومات صحيحة ودقيقة، وإلا فـ "القمامة داخل، والقمامة خارج!" (Garbage In, Garbage Out)!
دعنا نتعرف على خطوات هذه الرحلة:
الخطوة الاولى :
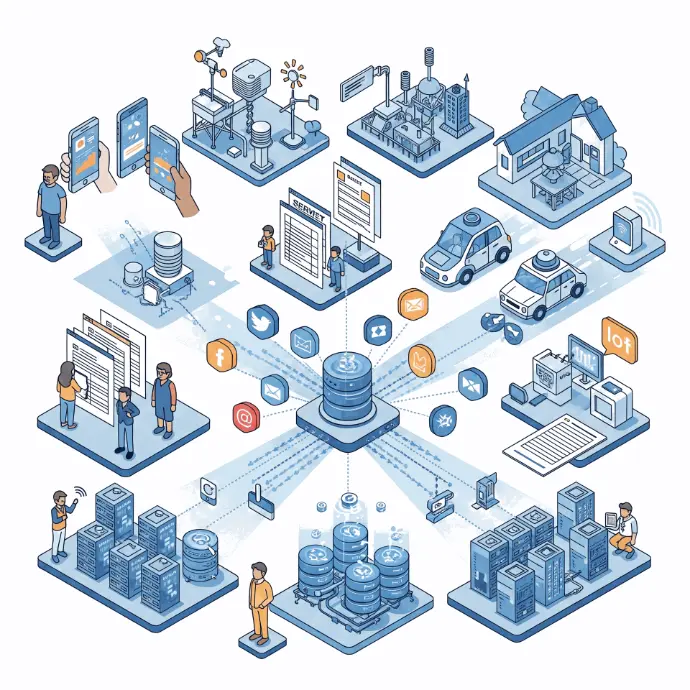
الجمع (Data Collection):
هذه هي الخطوة الأولى حيث يتم الحصول على البيانات. يمكن جمع البيانات من مصادر لا حصر لها، مثل:
المستشعرات (Sensors):
مثل المستشعرات في الهواتف الذكية (تسجل الحركة، الموقع)، أو مستشعرات الطقس، أو المستشعرات في السيارات ذاتية القيادة.
الاستبيانات والاستطلاعات (Surveys & Questionnaires):
لجمع آراء الناس وتفضيلاتهم.
الإنترنت ومواقع الويب (Internet & Web Scraping):
جمع النصوص والصور ومقاطع الفيديو من صفحات الويب، وسائل التواصل الاجتماعي، وقواعد البيانات المتاحة للعامة.
قواعد البيانات (Databases):
بيانات العملاء، سجلات المبيعات، المعلومات المالية المخزنة في أنظمة الشركات.
الأجهزة الذكية (IoT Devices):
كل الأجهزة المتصلة بالإنترنت تولد كميات هائلة من البيانات.
الخطوة الثانية :
التنظيف (Data Cleaning):
هذه هي من أهم وأكثر الخطوات استهلاكاً للوقت، ولكنها حاسمة جداً. فكر في البيانات كمنجم ذهب، تحتاج لتنظيف الصخور والأتربة للحصول على الذهب الخالص.
إزالة الأخطاء (Error Removal):
تصحيح الأخطاء الإملائية في النصوص، أو القيم غير المنطقية في الأرقام (مثلاً، عمر شخص 200 سنة!).
معالجة القيم المفقودة (Handling Missing Values):
ماذا تفعل إذا كان هناك خانة فارغة في البيانات؟ هل تملؤها بقيمة افتراضية، أم تحذف الصف كاملاً؟ القرار يعتمد على نوع البيانات.
إزالة التكرارات (Duplicate Removal):
حذف السجلات المكررة التي قد تؤدي إلى تضخيم غير صحيح لأهمية بعض البيانات.
تصحيح التنسيقات غير المتسقة (Inconsistent Formats):
توحيد طريقة كتابة التواريخ أو العناوين.
سيناريو "البيانات الملوثة": تخيل أنك تدرب نظام ذكاء اصطناعي للتعرف على الوجوه، وقمت بإدخال صور كثيرة لأشخاص ولكن بعض هذه الصور كانت مشوشة جداً، أو فيها وجوه حيوانات بدلاً من بشر، أو أسماء الأشخاص مكتوبة بشكل خاطئ. ما الذي سيحدث؟ سيتعلم نظام الذكاء الاصطناعي بشكل خاطئ! قد يفشل في التعرف على الوجوه بوضوح، أو يتعرف على الحيوانات كبشر، أو يربط الأسماء الخاطئة بالوجوه. هذا هو بالضبط معنى "القمامة داخل، القمامة خارج" – إذا كانت البيانات سيئة، فإن النتائج ستكون سيئة أيضاً.

الخطوة الثالثة :
التحويل وهندسة الميزات (Data Transformation & Feature Engineering):
بعد التنظيف، نحتاج إلى جعل البيانات مفهومة ومناسبة لـ "عقل" نماذج الذكاء الاصطناعي.
1/ التحويل (Transformation):
تحويل النصوص إلى أرقام: نماذج الذكاء الاصطناعي تفهم الأرقام بشكل أساسي. لذا، يجب تحويل الكلمات والجمل إلى تمثيلات رقمية، مثل "تضمين الكلمات" (Word Embeddings) حيث تتحول كل كلمة إلى متجه رقمي يعبر عن معناها وعلاقتها بكلمات أخرى.
توحيد المقاييس (Scaling): إذا كانت لديك بيانات مثل "العمر" (من 1 إلى 90) و "الدخل" (من 1000 إلى 100000)، فإن الذكاء الاصطناعي قد يولي اهتماماً أكبر للدخل لأنه أرقامه أكبر. توحيد المقاييس يجعل كل البيانات على نفس النطاق، وهذا مهم جداً.
2/ هندسة الميزات (Feature Engineering):
هي عملية إنشاء "ميزات" (Features) جديدة من البيانات الموجودة لجعلها أكثر فائدة للنموذج. مثلاً، إذا كان لديك تاريخ الميلاد، يمكنك اشتقاق "العمر" منه. أو إذا كان لديك سجلات لمشتريات عميل، يمكنك إنشاء ميزة "متوسط قيمة سلة المشتريات" لهذا العميل. هذه الميزات الجديدة تساعد الذكاء الاصطناعي على فهم الأنماط بشكل أفضل.
الخطوة الرابعة :
التقسيم (Data Splitting):
الآن، أصبحت البيانات نظيفة ومُحضَّرة. قبل تدريب نموذج الذكاء الاصطناعي، يجب تقسيمها إلى ثلاثة مجموعات رئيسية:
1/ مجموعة التدريب (Training Set):
جزء صغير من البيانات (عادة 10-20%) لا يراه النموذج أثناء التدريب أبداً. تُستخدم هذه المجموعة لـ "اختبار" أداء النموذج بعد الانتهاء من تدريبه، وقياس مدى دقته على بيانات جديدة لم يسبق له رؤيتها.
2/ مجموعة الاختبار (Test Set):
جزء صغير من البيانات (عادة 10-20%) لا يراه النموذج أثناء التدريب أبداً. تُستخدم هذه المجموعة لـ "اختبار" أداء النموذج بعد الانتهاء من تدريبه، وقياس مدى دقته على بيانات جديدة لم يسبق له رؤيتها.
3/ مجموعة التقييم/التحقق (Validation Set - أحياناً تُدمج مع الاختبار):
جزء صغير (عادة 10%) يستخدم لضبط إعدادات النموذج أثناء عملية التدريب. يمنع هذا من أن "يحفظ" النموذج البيانات ويصبح غير فعال على بيانات جديدة (مشكلة تُسمى Overfitting).